Antecedentes históricos
En septiembre de 1993 lo más excitante del World Wide Web eran su novedad y las inmensas posibilidades de futuro que se le adivinaban. Pero el «universo de información accesible por la red» pregonado por Tim Berners-Lee desde el CERN era aún sólo una promesa. Había, en todo el mundo, menos de cien servidores públicos. Sistemas jerárquicos de ficheros como FTP y Gopher y bases de datos como WAIS eran más ampliamente utilizados por la comunidad de Internet.
Ese mismo mes apareció en el directorio del CERN el primer servidor web localizado en España: el del Departamento de Educación de la Universitat Jaume I de Castellón (UJI). Sus responsables eran los mismos del primer servidor gopher español, instalado un año antes en esta misma universidad: un grupo informal integrado por Jordi Adell, del Departamento de Educación, y unos cuantos entusiastas del Servicio de Informática.
En diciembre había ya un total de 13 servidores web en España, todos ellos en universidades y centros de investigación conectados por RedIRIS. Jordi tuvo la iniciativa de situarlos en un mapa que funcionase como directorio visual de la Internet en España. Desde luego el diseño gráfico no era el punto fuerte del invento: la primera versión se digitalizó directamente de un mapa escolar del «Estado de las Autonomías» adquirido un rato antes. Pero eso era lo de menos: lo importante era el concepto. De hecho en cierta universidad de la cornisa cantábrica no tuvieron reparos en copiarse nuestro humilde mapa (!), con lo que alguien se ahorró treinta y cinco pesetas y el paseo hasta la papelería más próxima.
Durante el año siguiente, 1994, el crecimiento demográfico de Internet fue exponencial en los EEUU, en Europa y también en España. Su carácter pionero convirtió el «Mapa de recursos Internet» de la UJI en el punto de referencia para orientarse en el ciberespacio español: lo que ahora se llama un portal. Para ser visible en Internet había que figurar en el mapa, y Jordi empezó a recibir montones de correo. Tuvo que hacer filigranas para meter tanto servidor en un espacio tan reducido. Pronto hubo que recurrir a una serie de mapas autonómicos separados. Pero para 1995 estaba claro que eso no sería suficiente: simplemente no cabían. Si queríamos seguir adelante con el directorio habría que reconvertirlo en algún tipo de base de datos automatizada. Buscamos inspiración en el exterior. Las opciones disponibles se resumían básicamente en dos: el catálogo temático estilo Yahoo y el índice de palabras a la manera de Altavista.
Jordi consiguió convencer a unas cuantas personas para meterse a fondo en el tema: Enric Navarro, Toni Bellver y Carles Bellver, del Servicio de Informática, e Ismael Sanz, becario del proyecto Euroinfo. Íbamos a trabajar desinteresadamente y en nuestro tiempo libre, puesto que el grupo no tenía ningún tipo de reconocimiento ni respaldo oficial. Nuestra iniciativa podía ser entendida y apreciada en el resto del mundo, pero no necesariamente dentro de la Universidad, dónde se nos pagaba por hacer otras cosas. Aún así nos embarcamos, ilusionados por participar en algo nuevo e importante. Nuestra motivación era doble:
- Mantener el directorio como un observatorio privilegiado de la evolución de la Internet en España.
- Experimentar con algunas tecnologías de la información nuevas e interesantes, principalmente la indexación de textos y los lenguajes de etiquetas (markup languages).
Fundamentos técnicos
Lo primero fue tomar algunas decisiones filosóficas que enmarcasen el proyecto. En parte eran consecuencia directa de nuestras posibilidades e intereses:
- Limitar el ámbito del directorio a España: se trataba de poner límites razonables al volumen de datos que iba a manejar un sistema experimental.
- Primar el registro voluntario de los recursos y su catalogación mediante descriptores elegidos por sus responsables, en vez de indexar indiscriminadamente todos los contenidos recuperados por un robot. O sea, una tercera vía entre Altavista y Yahoo.
- Primar las búsquedas libres frente a las listas geográficas y/o temáticas predeterminadas.
- Extractar información estadística de las búsquedas realizadas y los enlaces preferidos por los usuarios.
- Basar el sistema en software libre y desarrollos propios.
|
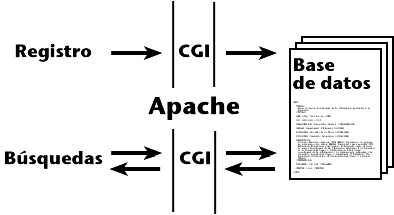
El sistema que diseñamos consistía esencialmente en una base de datos más un servidor web como interfaz de comunicación con los usuarios. Tanto el registro de recursos como las búsquedas de información se realizarían mediante formularios. Un servidor Apache vehicularía las peticiones hacia la base de datos y devolvería los resultados según la norma CGI (Common Gateway Interface). Nada del otro mundo. Lo único original era la base de datos: una colección de documentos estructurados que describían los recursos por medio de etiquetas estilo HTML (Hypertext Markup Language):
<REC>
<TITULO>
Grupo de Nuevas Tecnologías de la Información aplicadas a la
Educación
</TITULO>
<URL> http://nti.uji.es </URL>
<ID> 94020200000 </ID>
<ORGANIZACION> Universitat Jaume I </ORGANIZACION>
<UNIDAD> Departament d’Educació </UNIDAD>
<LOCALIDAD> Castelló de la Plana </LOCALIDAD>
<COMUNIDAD> Comunitat Valenciana </COMUNIDAD>
<DESCRIPCION>
Contiene diversos recursos: HTML BBEdit Extensions, un paquete
de extensiones del editor BBEdit (Macintosh) para escribir HTML.
Biblioteca Electrónica Joan Fuster. Información sobre el Grupo
de Nuevas Tecnologías de la Información aplicadas a la Educación
de la Universitat Jaume I. Publicaciones sobre nuevas
tecnologías de la información y la comunicación aplicadas a la
educación. Universitat Jaume I. Department of Education. The
Department of Education of the Universitat Jaume I, Castello.
(Spain).
</DESCRIPCION>
<FECHAREG> 1/9/1993 </FECHAREG>
<STATUS> 00000 </STATUS>
</REC>
|
El éxito y la enorme difusión del HTML era una demostración práctica de las ventajas y el potencial de los lenguajes de etiquetas. Pero el HTML, con su limitado e inflexible conjunto de etiquetas, se quedaba muy corto. De ahí las sucesivas revisiones y propuestas de ampliación: HTML 2.0, HTML+, HTML 3.2, etc. Todo se arreglaría si cada uno pudiese usar sus propias etiquetas, las adecuadas a su campo de trabajo. Eso sí lo permitía el SGML (Standard Generalized Markup Language), una norma más amplia de la que el HTML era una aplicación particular. Pero el SGML exige para empezar una rigurosa descripción de la sintaxis de tus etiquetas en un complejo y poco menos que cabalístico documento llamado Document Type Definition (DTD). Nosotros nos saltamos tan engorroso trámite: nos limitamos a usar nuestras etiquetas de una manera más o menos coherente. Total, nadie iba a enterarse. Desde luego no podíamos evitar cierta sensación de chapuza, pero el entusiasmo que despertó el XML (Extensible Markup Language) a partir de 1998 nos alivió: se trataba fundamentalmente de la misma chapuza, sólo que justificada teóricamente y avalada por el World Wide Web Consortium.
Con esto teníamos la información estructurada. Faltaba aún la segunda parte, igualmente esencial: un motor que gestionase, facilitase y acelerase las búsquedas mediante índices. Partimos de la base teórica de WAIS, un clásico de los sistemas de recuperación de información, y lo reinventamos para acoplarlo a nuestro pseudo XML. Lo llamamos Simple, porque no se nos ocurría un nombre mejor, y constaba grosso modo de dos módulos: uno encargado de generar y mantener los índices de colecciones de documentos, y otro encargado de las búsquedas, con soporte para lógica booleana y lenguaje natural. Un índice Simple incluye, para cada palabra, información acerca de los documentos en los que aparece y en qué contexto, o sea, dentro de qué etiquetas. Esto nos permitía:
- realizar búsquedas más inteligentes, por ejemplo hallar los recursos relacionados con cierto tema que estuviesen localizados en la Comunidad de Madrid.
- sopesar mejor la relevancia: cuenta más una palabra en el título o en el URL que en la descripción, por ejemplo.
Las tareas se distribuyeron aproximadamente como sigue:
- Jordi y Toni diseñaron el sistema en su conjunto y coordinaron su desarrollo.
- Jordi diseñó la estructura de datos.
- Enric se encargó de configurar y mantener el servidor: una máquina Unix, de cuya marca no haremos publicidad gratis, heredada de un proyecto de investigación anterior.
- Carles diseñó y programó Simple.
- Ismael programó la interfaz de búsquedas entre Apache y Simple, la interfaz de inyección de registros en la base de datos y las utilidades estadísticas.
Otra cosa que hizo Jordi fue ponerle nombre al sistema: dónde, acrónimo de Directorio Online de España. En realidad era una referencia a la frase que William Gibson tomó de Gertrude Stein para explicar el ciberespacio: «There is no there, there», traducible más o menos como «No hay un dónde, allí.» Dónde estuvo listo y en marcha el 1 de junio de 1996 con 1.157 registros en la base de datos. A partir de ese día Jordi se ocupó de supervisar su funcionamiento diario. Los demás, en comparación, puede decirse que nos retiramos a descansar, aunque seguimos vigilando de reojo. Carles parcheó Simple alguna que otra vez, para corregir fallos o por ejemplo para añadirle soporte parcial de metadatos y del formato PDF. En 1997 lo aprovechó para incorporar una facilidad de búsquedas al Servei d'Informació del Campus (SIC) de la UJI, donde a día de hoy todavía se usa.
Auge y caída
Tanto las consultas a la base de datos como el registro de nuevos recursos experimentaron un incremento espectacular durante los primeros meses. A principios de 1997 estábamos en 5.000 registros y 3,5 millones de accesos al mes. Después el número de consultas creció más lentamente. El tope lo alcanzamos en junio de 1998, dos años después de inaugurar el servicio, con 29.000 registros y casi 5 millones de consultas en un mes: una media de más de 100 por minuto. A partir de ahí nos estancamos. El número de registros siguió aumentando, pero las consultas no. La razón era el colapso del servidor: no daba abasto, no admitía más usuarios.
La solución pasaba por:
- ampliar el servidor: un microprocesador más rápido, más memoria RAM, más y mejor almacenamiento, mejor conexión a la red, etc.
- remodelación a fondo de Simple para mantener el índice permanentemente en RAM y reemplazar CGI por otra interfaz más eficiente como FastCGI o mod_perl.
- dedicar recursos humanos, además, a la administración de la base de datos: una de las conclusiones que sacamos de nuestra experiencia es que asegurar la calidad de la información requiere revisarla y depurarla. Los filtros automáticos ayudan, pero no son terminantes.
Nada de eso estaba en nuestras manos, desgraciadamente. Nuestro grupo, ya lo hemos dicho, era absolutamente informal. Carecíamos de infraestructura y recursos con los que afrontar la situación, complicada, además, por la feroz competencia en el reciente mercado de «portales»: uno no tenía nada que hacer si no ofrecía otros servicios además del directorio, como correo electrónico, noticias de actualidad, el parte meteorológico, etc. Demasiado para nosotros.
Cuando empezamos a perder usuarios decidimos dar por terminado el experimento. Al fin y al cabo ya había dado sus frutos durante un tiempo considerable. Durante tres largos años nos habíamos divertido jugando con etiquetas e índices y habíamos recopilado abundantes datos estadísticos acerca de la evolución demográfica de la Internet en España y de los intereses y necesidades de los internautas. Con 44.563 registros en la base de datos, dónde anunció que cerraba sus puertas el 1 de junio de 1999.
Epílogo: ¿Ave Fénix?
El principio del fin es una anécdota: antes de su cierre definitivo y oficial dónde dejó de funcionar durante un par de días porque un operario del Servicio de Informática al que no le sonaba que aquello aún estuviese en marcha le dio al botón y apagó el servidor. Literalmente.
La anécdota es significativa. Durante sus tres años de existencia, dónde pasó relativamente desapercibido en la UJI. Luego, anunciamos el cierre y la abrumadora reacción del público sorprendió a todo el mundo y contribuyó a concienciarnos acerca de la importancia estratégica de las nuevas tecnologías. Algunos cargos se enteraron de lo que había significado dónde para los comienzos de la Internet en España y el mundo de habla hispana en general, y para la propia institución, cuando llegó un alud de mensajes de correo preguntando por qué cerrábamos, ofreciendo su ayuda si servía de algo, o expresando su pesar: éste fue su primer buscador, y aunque ahora ya no lo utilizaban mucho, lamentaban igualmente lo sucedido.
Desde entonces ha llovido mucho por aquí. La Universitat Jaume I ha creado un nuevo Centro de Educación y Nuevas Tecnologías (CENT) dirigido por Jordi Adell al que se han incorporado también Toni Bellver y Carles Bellver como personal técnico. Los plazos y la lentitud inherente a las organizaciones han hecho que a noviembre de 2000 aún estemos inmersos en la puesta en marcha del Centro. En cuanto al futuro, una de las ideas que circularon fue la de reflotar o resucitar dónde. No creemos que sea lo más adecuado. Los portales generalistas se han convertido en puro negocio, un negocio de miles de millones totalmente ajeno al espíritu de una institución universitaria. Para nosotros es el momento de ir más allá, innovar y especializarse. Nuestro campo es la educación, concretamente la aplicación educativa de las nuevas tecnologías, y en eso estamos. Tenemos algunos proyectos que empezarán a materializarse en breve.
Firmado: lo que queda del grupo
Rev. 4/12/2000